

软件介绍
tesseract-ocr是一款免费的开源图像OCR文字识别软件。你只要提供他一个命令,它就能根据你的命令将你想要识别的图片中的文字转换成文本的形式。到目前为止,它已经支持简体中文、繁体中文、英文、日文、韩文等等60多种语言的识别。并随着大家对它功能上的要求在不断改进、不断消除bug、优化功能。有需要的朋友欢迎前来下载tesseract ocr 中文版,小编在安装包还未大家附上了中文包哦!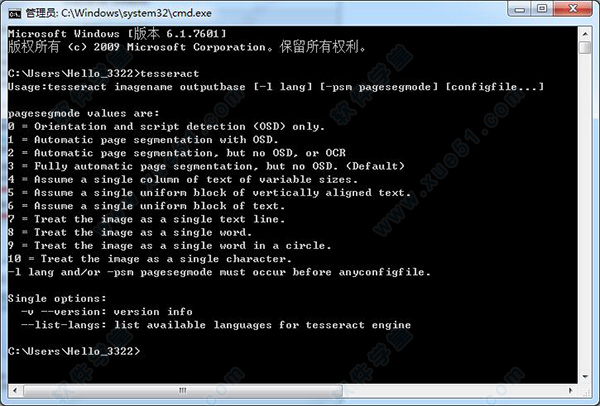
安装教程
1、在本站下载解压好安装包,双击运行“tesseract-ocr-setup-3.02.02.exe”tesseract ocr 中文版开始安装软件,点击“是”。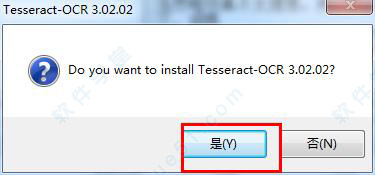
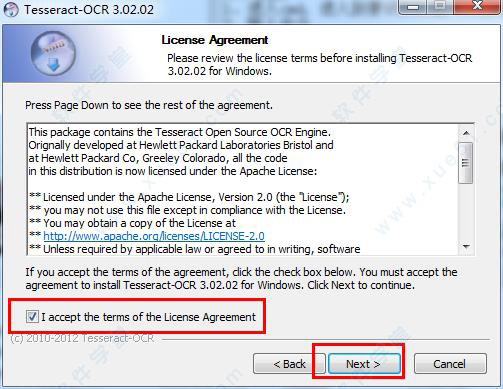
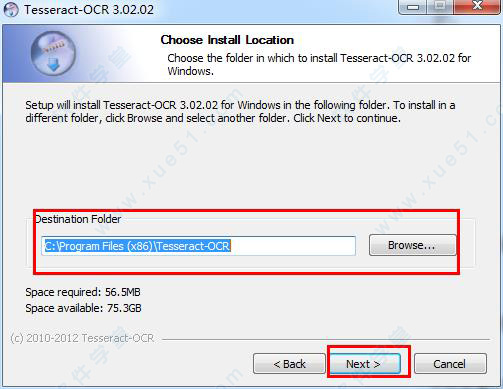
2、根据下面图片上的教程,连续点击“next”。


3、到了语言库的选择,你要使用到哪种语言就勾选哪种,默认是一种都不勾选,然后点击“next”。

4、然后点击“install”,开始正式安装,安装完成之后点击“next”。
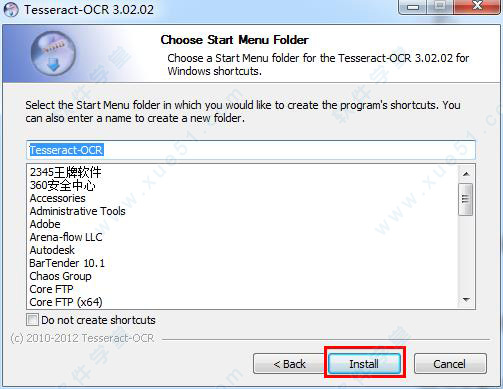

5、全部安装完成点击“finish”,tesseract ocr 中文版安装结束。
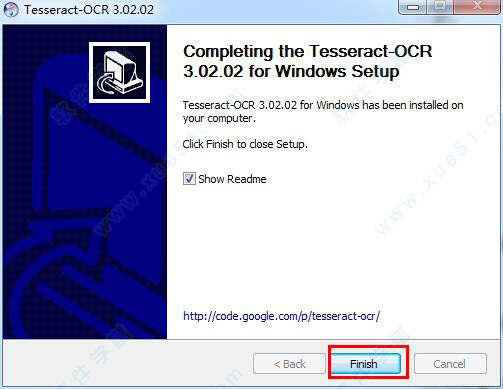
6、检验是否安装成功,运行(win+R)—输入“cmd”—输入“tesseract”,然后会出现下图所示的的情况那就是安装成功了。

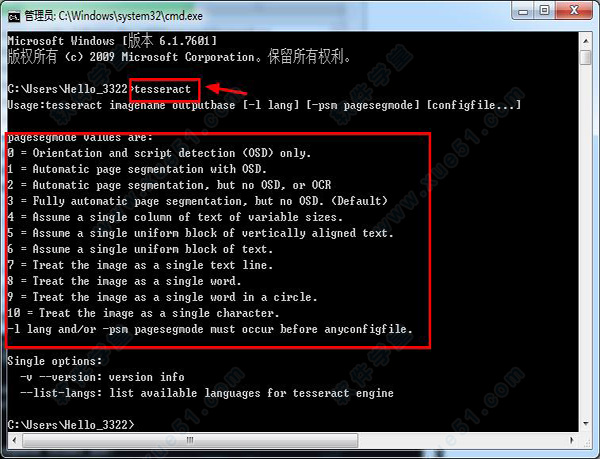
使用教程
基本使用介绍1、我准备了一张验证码1.jpg放置在D盘的根目录下,验证码图:

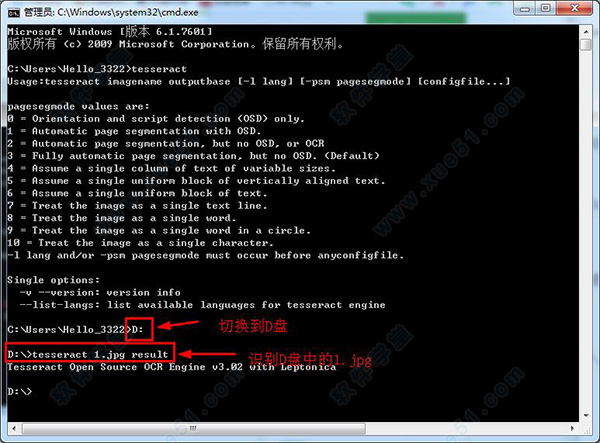
2、然后输入“D:”,回车,输入“tesseract 1.jpg result”,意思为:识别D盘中1.jpg图片中的内容,将结果输出到result.txt的文件中。
3、结果如图说是:

Tesseract-OCR识别中文与训练字库使用介绍
一、准备工作
1、下载引擎,注意要3.0以上才支持中文哦,按照提示安装就行。
2、下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到项目的tessdata文件夹里面。
3、下载jTessBoxEditor,这个是用来训练字库的。
以上的几个在百度都能找到下载,就不详细讲了。

二、识别
1、进入cmd,进入到要识别的图片的路径下。
2、输入命令
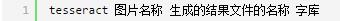
例如我的图片识别就是:


识别完后会生成result.txt文件

当然啦效果不太理想。所以我们要训练自己的字库。
三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。


box文件和对应的tif一定要在相同的目录下,不然后面打不开。
3、打开jTessBoxEditor矫正错误并训练
打开train.bat
找到tif图,打开,并校正。

4、训练。
只要在命令行输入命令即可。

在这我明明已经矫正好了,但是还是有1个字符不能识别出来,报的错跟实际上完全没有相关性,不知道是不是bug,到后面的结果就是“园”字没有识别出来。
先不管,毕竟只有一个样本。
新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
继续敲命令
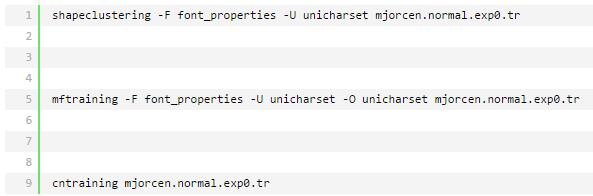
最后会生成五个文件,把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
如图:
命令行输入,合并五个文件:

得到训练好的字库。

四、测试
1、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
2、识别命令:

3、效果
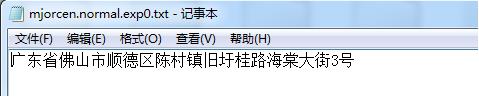
对比:
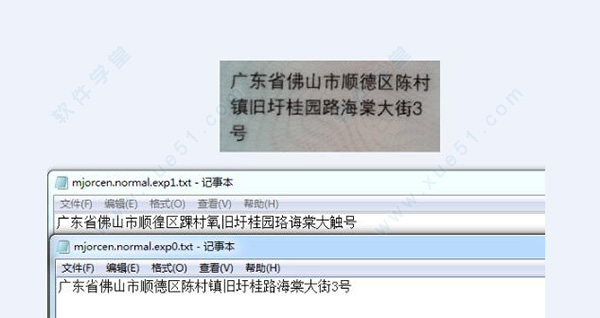
总结:肯定要自己训练过后的字库识别效果好,接下来要把整个项目弄进android,还要研究怎么将多个字库合并成一个字库,因为我不可能一次训练完所有的图片文字的。到时候有什么成果了再分享博文。希望大家可以点赞!谢谢。
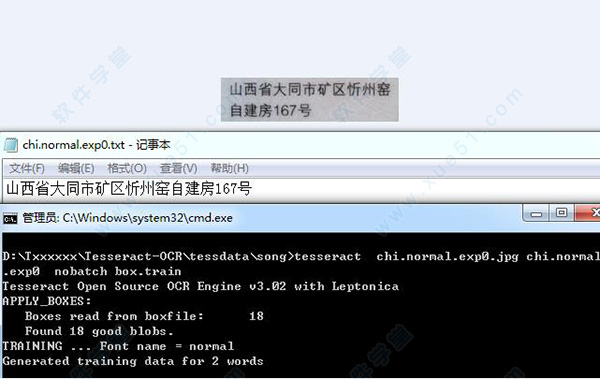
更新:没有错误的话命令行的提示应该是这样的
附录
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract 1.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract 1.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdataconfigs 和 tessdatatessconfigs 目录下的文件名
同类软件






用户评论
所有评论(
5)
精彩推荐










本类精品推荐
-
下载

- 天天盈球app官方版
- 资讯阅读
-
下载

- 52书库app最新版
- 资讯阅读
-
下载

- 亲宝宝成长记录相册app官方版
- 生活实用
- 4 下载 潇湘高考app官方版
- 5 下载 蚌埠论坛手机版
- 6 下载 addons最新版
- 7 下载 可乐助手王者荣耀单机全皮肤版
- 8 下载 趣打印破解版
- 9 下载 mooncell安卓版
- 10 下载 qq安全中心最新版本
 浙公网安备 申请中
浙公网安备 申请中